 Ma formation SEO personnalisée aide les gros sites internet à résoudre leurs problèmes de duplicate content. L’agence SEO Duo Diff a le plaisir de vous dévoiler le chapitre de sa formation SEO sur le duplicate content
Comment choisir une formation SEO ? Commencez par effectuer une recherche sur « formation SEO » et regardez ceux qui sont positionnés sur les résultats de recherche organique de Google (pas les résultats payants en haut…). Ce sont tous des spécialistes qui comprennent et maîtrisent le SEO d’aujourd’hui.
Ceux qui sont là, c’est quand même pas du hasard, non ? (vous voyez brandaroundtheweb, agence dont je suis cofondateur ? alors vous me voyez 🙂
Bon, assez de démonstrations, passons à la partie de la formation SEO qui parle du contenu dupliqué souvent générer sur les gros sites avec les urls dynamiques, une horreur à gérer en matière de SEO qui demande une rigueur sans faille.
Ma formation SEO personnalisée aide les gros sites internet à résoudre leurs problèmes de duplicate content. L’agence SEO Duo Diff a le plaisir de vous dévoiler le chapitre de sa formation SEO sur le duplicate content
Comment choisir une formation SEO ? Commencez par effectuer une recherche sur « formation SEO » et regardez ceux qui sont positionnés sur les résultats de recherche organique de Google (pas les résultats payants en haut…). Ce sont tous des spécialistes qui comprennent et maîtrisent le SEO d’aujourd’hui.
Ceux qui sont là, c’est quand même pas du hasard, non ? (vous voyez brandaroundtheweb, agence dont je suis cofondateur ? alors vous me voyez 🙂
Bon, assez de démonstrations, passons à la partie de la formation SEO qui parle du contenu dupliqué souvent générer sur les gros sites avec les urls dynamiques, une horreur à gérer en matière de SEO qui demande une rigueur sans faille.
Formation SEO sur le duplicate content
Chapitre 1 de cette formation SEO, Le duplicate content c’est quoi ?
Le duplicate content survient lorsque 2 pages ou plus partagent le même contenu comme dans le dessin ci-dessous. Simple non ? Le problème est que les webmasters pensent qu’une page est un fichier sur leur serveur alors que pour Google chaque url est une page. Et, avec des gros sites contenant des urls dynamiques, il est facile de voir se créer plusieurs urls qui mènent vers le même contenu par des chemins différents.
Simple non ? Le problème est que les webmasters pensent qu’une page est un fichier sur leur serveur alors que pour Google chaque url est une page. Et, avec des gros sites contenant des urls dynamiques, il est facile de voir se créer plusieurs urls qui mènent vers le même contenu par des chemins différents.
Formation SEO chapitre 2 : Quel est le problème du Duplicate Content ?
D’un point de vu SEO, le duplicate content était un problème bien avant Google Panda. Ci-dessous un bref aperçu des problèmes de duplicate content durant ces dernières années. L’index supplémentaire secondaire Dans les premiers jours de Google, le simple fait d’indexer le web était un immense challenge computationnel. Pour gérer le problème, certaines urls analysées comme duplicate ou pauvre en contenu étaient stocké dans un index secondaire appelé ‘supplemental index ». Ces urls, d’un point de vu SEO étaient des urls de seconde classe sans aucune chance de pouvoir se positionner. En 2006, Google a intégré l’index secondaire dans l’index principal sans aucun changement visible dans les résultats de recherche. Les urls de l’index secondaire étaient filtrés des résultats de recherche par des règles implantés dans l’algorithme. Le budget du “crawl” Il n’y a pas vraiment de limite au crawl des pages, d’autant que la vitesse du crawl a considérablement augmenté ces dernières années, mais si Googlebot rencontre trop d’urls aux contenus identiques sur votre site, il risquera de laisser tomber l’indexation des pages. S’il y a trop de chemins différents avec des urls différents qui mènent au même contenu, Google abandonneras. Du coup, les pages aux contenus uniques que vous voulez que Google index risquent de ne même pas être visités par Googlebot du tout. Au mieux, ils seront crawler moins souvent. Vous pouvez avoir un ressenti du crawl de votre site en allant dans Outils pour les Webmasters de Google en allant dans « exploration » puis « statistiques sur l’exploration ». Le “cap” de l’indexation Il n’y a pas de “cap” sur le nombre de pages que Google indexera sur un site. Il semble y avoir une limite dynamique lié à l’autorité du site. Si vous remplissez votre index de pages inutiles et dupliqués, vous pouvez exclure des pages importantes et plus profonde de l’index. Par exemple, si vous avez des milliers de résultats de recherches internes, Google risque de ne pas indexer l’ensemble de vos pages produits (menus à facettes par exemple). C’est une erreur de croire que plus de pages indexées c’est mieux. Bien souvent c’est le contraire. Toute chose étant égal, des indexes bourrés d’urls diluent votre habilité à vous positionner, surtout avec des urls à contenus identiques. La mise à jour Panda Bien avant l’avènement de Panda, il y a eu de nombreuses discussions sur l’éventualité d’une pénalité du au contenus dupliqués. En fait la réponse était sémantique. Google n’index pas 2 fois le même contenu, un point c’est tout. Depuis l’arrivée de Panda en Février 2011 (Août 2011 en France), l’impact sur le duplicate content a été bien plus sévère. Avant Panda, seul les pages de contenus dupliqués étaient impactés. Depuis Panda, c’est le site entier qui peut être impacté. Si vous êtes touché par Panda, même les pages de contenu unique peuvent être impactées, voir même désindexées.Formation SEO chapitre 3 : Il y a 3 sortes de Duplicate Content
(1) Les True Duplicates Une « True Duplicate » est une page identique (en contenu) à une autre page. Ces pages ne diffèrent que par l’url : (2) Near Duplicates
Une “Near Duplicate” diffère d’une autre page (ou pages) seulement en partie. Cela peut être un bloc de texte, une image (même nom et balise alt) voir même l’ordre du contenu.
(2) Near Duplicates
Une “Near Duplicate” diffère d’une autre page (ou pages) seulement en partie. Cela peut être un bloc de texte, une image (même nom et balise alt) voir même l’ordre du contenu.
 Une définition exacte d’un contenu identique en partie est difficile à définir. Plus plus loin dans la formation SEO.
(3) Cross-domain Duplicates
Une “cross-domain duplicate” arrive lorsque 2 sites partagent le même contenu.
Une définition exacte d’un contenu identique en partie est difficile à définir. Plus plus loin dans la formation SEO.
(3) Cross-domain Duplicates
Une “cross-domain duplicate” arrive lorsque 2 sites partagent le même contenu.
 Ces pages dupliquées peuvent être “true” ou “near”. Et contrairement à ceux que certains pensent, des pages de contenus dupliqués entre sites peuvent représenter un problème pour le contenu légitime originel (d’où l’intérêt de lié une page Google+ à son site pour partager immédiatement tout nouveau contenu pour acquérir l’authorship aux yeux de Google, élémentaire non ?).
Ces pages dupliquées peuvent être “true” ou “near”. Et contrairement à ceux que certains pensent, des pages de contenus dupliqués entre sites peuvent représenter un problème pour le contenu légitime originel (d’où l’intérêt de lié une page Google+ à son site pour partager immédiatement tout nouveau contenu pour acquérir l’authorship aux yeux de Google, élémentaire non ?).
Chapitre 4 de la formation SEO : Les outils pour solutionner le Duplicate Content
(1) 404 (Not Found) Le moyen le plus simple est de supprimer le contenu dupliqué en renvoyant une erreur 404. Si le contenu n’a aucune valeur pour les visiteurs et qu’il n’y a pas ou peu de trafic et de liens entrants, alors le retirer est une option valide. (2) Redirection 301 Une autre manière d’enlever une page de contenu dupliqué est de faire une redirection 301. La redirection 301 indique aux moteurs de recherche que la page a été définitivement déplacée vers une autre url. D’un point de vu SEO, la plupart du bénéfice des liens entrants de l’ancienne page profite à la nouvelle. C’est une bonne option pour supprimer un contenu dupliqué. L’utilisation d’une url canonique peut aussi s’avérer pertinent, mais c’est un autre sujet. (3) Robots.txt Une autre option consiste à laisser le duplicate content visible aux visiteurs, mais de le bloquer aux robots des moteurs de recherché avec un fichier robots.txt. Cela ressemble à ceci : Un des avantages d’utiliser un fichier robots.txt est qu’il est relativement facile de bloquer des répertoires complets, voir même des paramètres urls. L’inconvénient est que c’est une solution souvent extrême et parfois même peu fiable. De plus, cela n’enlèvera pas le contenu déjà indexé. Cela décourage aussi les robots des moteurs de recherche à venir crawler votre site et ils ne recommandent pas l’utilisation de robots.txt pour résoudre le problème de Duplicate Content.
(4) Meta Robots
Vous pouvez également utiliser la méta robots appelé aussi noindex sur le code source des pages dans la partie « header » comme ceci :
Un des avantages d’utiliser un fichier robots.txt est qu’il est relativement facile de bloquer des répertoires complets, voir même des paramètres urls. L’inconvénient est que c’est une solution souvent extrême et parfois même peu fiable. De plus, cela n’enlèvera pas le contenu déjà indexé. Cela décourage aussi les robots des moteurs de recherche à venir crawler votre site et ils ne recommandent pas l’utilisation de robots.txt pour résoudre le problème de Duplicate Content.
(4) Meta Robots
Vous pouvez également utiliser la méta robots appelé aussi noindex sur le code source des pages dans la partie « header » comme ceci :
 Cette directive indique aux robots de ne pas indexé la page ni suivre les liens contenus dedans. C’est mieux d’un point de vu SEO que le robots.txt. De plus il peut être généré dynamiquement dans le code, ce qui est plus flexible.
L’autre valeur utilisé est « NOINDEX, FOLLOW » en demandant aux robots de ne pas indexé la page mais de suivre les liens dans le contenu de la page. Ce qui peut être utile pour des pages de résultats de recherche interne par example en bloquant certaine variations d’urls tout en suivant les liens vers des pages produits.
Nota : Il ne sert absolument à rien d’ajouter une méta robots tag avec « INDEX, FOLLOW » à une page puisque toute page est indexé par défaut.
(5) Rel=Canonical
En 2009, les moteurs de recherche se sont mis d’accord pour créer la directive rel=canonical. Cela permet aux webmasters de définir une version canonique pour chaque page. Ce tag va dans le header de la page dont voici un exemple :
Cette directive indique aux robots de ne pas indexé la page ni suivre les liens contenus dedans. C’est mieux d’un point de vu SEO que le robots.txt. De plus il peut être généré dynamiquement dans le code, ce qui est plus flexible.
L’autre valeur utilisé est « NOINDEX, FOLLOW » en demandant aux robots de ne pas indexé la page mais de suivre les liens dans le contenu de la page. Ce qui peut être utile pour des pages de résultats de recherche interne par example en bloquant certaine variations d’urls tout en suivant les liens vers des pages produits.
Nota : Il ne sert absolument à rien d’ajouter une méta robots tag avec « INDEX, FOLLOW » à une page puisque toute page est indexé par défaut.
(5) Rel=Canonical
En 2009, les moteurs de recherche se sont mis d’accord pour créer la directive rel=canonical. Cela permet aux webmasters de définir une version canonique pour chaque page. Ce tag va dans le header de la page dont voici un exemple :
 Lorsque les moteurs de recherche arrivent sur une page avec un tag canonical, ils attribuent la page à l’url canonique que vous avez définie, sans prendre en compte l’url qui les a dirigés vers cette page. Par exemple, si un robot atteint la page ci-dessus avec l’url www.example.com/index.html, le moteur de recherche n’indexera pas l’url non-canonique additionnel.
Très important : Faites attention de ne pas inclure une url canonical identique dans le header de tout votre site, mais d’affecter l’url canonical à chaque page de votre site. Sinon, les résultats pourraient être catastrophiques. Votre site ou votre cms doit être bien codé pour éviter cela. Affichez le code source de vos pages pour vérifier que les urls canoniques correspondent bien à la page et pas à celle de la page d’accueil.
(6) Google URL à supprimer
Dans outils pour les webmasters de Google vous pouvez demander à ce qu’une page (ou un répertoire) soit manuellement retirer de l’index (voir image ci-dessous)
Lorsque les moteurs de recherche arrivent sur une page avec un tag canonical, ils attribuent la page à l’url canonique que vous avez définie, sans prendre en compte l’url qui les a dirigés vers cette page. Par exemple, si un robot atteint la page ci-dessus avec l’url www.example.com/index.html, le moteur de recherche n’indexera pas l’url non-canonique additionnel.
Très important : Faites attention de ne pas inclure une url canonical identique dans le header de tout votre site, mais d’affecter l’url canonical à chaque page de votre site. Sinon, les résultats pourraient être catastrophiques. Votre site ou votre cms doit être bien codé pour éviter cela. Affichez le code source de vos pages pour vérifier que les urls canoniques correspondent bien à la page et pas à celle de la page d’accueil.
(6) Google URL à supprimer
Dans outils pour les webmasters de Google vous pouvez demander à ce qu’une page (ou un répertoire) soit manuellement retirer de l’index (voir image ci-dessous)
 Mais, cela ne concerneras que Google, il faudra aussi le faire pour Bing, Yahoo… La demande de suppression d’une url dans OPW de Google est à utiliser en dernier recours si Google s’entête à garder l’url dans son index.
(7) Google Paramètres d’urls
Vous pouvez également utiliser “paramètres d’urls” pour spécifié des paramètres que vous souhaitez que Google ignore (ce qui bloque l’indexation des pages avec ces paramètres).
Mais, cela ne concerneras que Google, il faudra aussi le faire pour Bing, Yahoo… La demande de suppression d’une url dans OPW de Google est à utiliser en dernier recours si Google s’entête à garder l’url dans son index.
(7) Google Paramètres d’urls
Vous pouvez également utiliser “paramètres d’urls” pour spécifié des paramètres que vous souhaitez que Google ignore (ce qui bloque l’indexation des pages avec ces paramètres).
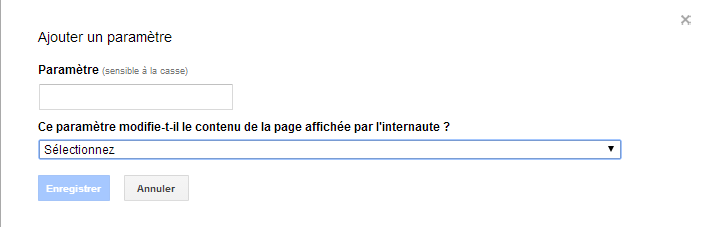 Ces changements n’affectent que Google bien sûr et Google peut décider de modifier vos paramètres à sa guise. A n’utiliser donc qu’en dernier recours.
(9) Rel=Prev & Rel=Next
En septembre 2011 Google permet la pagination des résultats de recherche pour combattre le near duplicate content. Essentiellement, les résultats paginés sont des recherches où les résultats sont divisés en blocs. Et chaque bloc a sa propre url.
Désormais vous pouvez indiquer à Google comment les contenus paginés sont connectés entre eux en utilisant les tags Rel-Prev et Rel-Next comme dans l’exemple ci-dessous :
Dans cet exemple, le robot de recherché a atterrit sur la page 3 des résultats de recherche et les tags rel= »prev » et rel= »next » indiquent une pagination vers la page 2 et la page 4.
Ces changements n’affectent que Google bien sûr et Google peut décider de modifier vos paramètres à sa guise. A n’utiliser donc qu’en dernier recours.
(9) Rel=Prev & Rel=Next
En septembre 2011 Google permet la pagination des résultats de recherche pour combattre le near duplicate content. Essentiellement, les résultats paginés sont des recherches où les résultats sont divisés en blocs. Et chaque bloc a sa propre url.
Désormais vous pouvez indiquer à Google comment les contenus paginés sont connectés entre eux en utilisant les tags Rel-Prev et Rel-Next comme dans l’exemple ci-dessous :
Dans cet exemple, le robot de recherché a atterrit sur la page 3 des résultats de recherche et les tags rel= »prev » et rel= »next » indiquent une pagination vers la page 2 et la page 4.
 (10) Le maillage interne du site
Rappelez-vous que la meilleure solution pour lutter contre le duplicate content est d’éviter d’en créer. Bien sûr, sauf que ce n’est pas toujours possible. Ceci dit, si vous commencer à avoir une douzaine de problèmes de duplicate à résoudre, vous devriez peut-être réexaminer votre maillage de liens interne et la structure de votre site.
Lorsque vous solutionner un problème de duplicate content avec une redirection 301, n’oubliez pas de changer les liens internes de votre site en remplaçant l’ancienne url par la nouvelle. Les liens internes sont des signaux forts alors, si vous envoyer dans votre sitemap des urls comprenant des liens avec l’ancienne url, vous risquez de perdre en crédibilité et de vous causer des problèmes.
(11) Rel= »alternate » hreflang= »x »
Depuis février 2012 Google a introduit une nouvelle façon de traiter les contenus traduits ainsi que de même langue avec des variations régionales (comme l’anglais US vs l’anglais UK). L’implémentation de ces tags est complexe et dépends des situations mais voici un guide complet en anglais hreflang= »x » attribute.
La meilleure solution d’un point de vu SEO reste l’hébergement du site sur un domaine régional en .us, .uk etc… Les purs players comme Amazon ne s’y trompent pas.
(10) Le maillage interne du site
Rappelez-vous que la meilleure solution pour lutter contre le duplicate content est d’éviter d’en créer. Bien sûr, sauf que ce n’est pas toujours possible. Ceci dit, si vous commencer à avoir une douzaine de problèmes de duplicate à résoudre, vous devriez peut-être réexaminer votre maillage de liens interne et la structure de votre site.
Lorsque vous solutionner un problème de duplicate content avec une redirection 301, n’oubliez pas de changer les liens internes de votre site en remplaçant l’ancienne url par la nouvelle. Les liens internes sont des signaux forts alors, si vous envoyer dans votre sitemap des urls comprenant des liens avec l’ancienne url, vous risquez de perdre en crédibilité et de vous causer des problèmes.
(11) Rel= »alternate » hreflang= »x »
Depuis février 2012 Google a introduit une nouvelle façon de traiter les contenus traduits ainsi que de même langue avec des variations régionales (comme l’anglais US vs l’anglais UK). L’implémentation de ces tags est complexe et dépends des situations mais voici un guide complet en anglais hreflang= »x » attribute.
La meilleure solution d’un point de vu SEO reste l’hébergement du site sur un domaine régional en .us, .uk etc… Les purs players comme Amazon ne s’y trompent pas.
Formation SEO chapitre 5 : Exemples de Duplicate Content
(1) “www” vs. Pas de-www Concernant l’ensemble du site, ceci est certainement le coupable prioritaire. Que vous ayez des mauvais chemins en interne ou que vous ayez attiré des liens ou des mentions sociales au mauvais url, vous avez la version « www » comme la version non « www » sur les urls indexés de votre site. La solution est de définir l’url canonique pour l’ensemble du site comme ceci :
Il vous suffira ensuite de l’inclure dans le code source dans la section header” de votre site.
Une fois que c’est fait vous pouvez indiquer à Google dans Outils pour les Webmasters l’adresse choisie sous paramètres du site ou laisser Google découvrir votre url canonique.
(2) Mise en scène d’un nouveau site (staging)
Lors de la refonte d’un site internet, un scenario typique est d’héberger votre nouveau site avec le contenu de l’ancien sur un sous domaine, voir même un domaine provisoire ce qui provoque du duplicate content sur deux urls comme ceci :
La solution est de définir l’url canonique pour l’ensemble du site comme ceci :
Il vous suffira ensuite de l’inclure dans le code source dans la section header” de votre site.
Une fois que c’est fait vous pouvez indiquer à Google dans Outils pour les Webmasters l’adresse choisie sous paramètres du site ou laisser Google découvrir votre url canonique.
(2) Mise en scène d’un nouveau site (staging)
Lors de la refonte d’un site internet, un scenario typique est d’héberger votre nouveau site avec le contenu de l’ancien sur un sous domaine, voir même un domaine provisoire ce qui provoque du duplicate content sur deux urls comme ceci :
 Idéalement, on solutionne ces problèmes par l’architecture du site. Dans la plupart des cas il vaut mieux mettre les pages sécurisées en NOINDEX. Les pages de caddies et de finalisation de commande n’ont rien à faire dans l’index de recherche. Je vous déconseille d’utiliser des redirections 301 des pages https vers leurs versions en http, vous risquez de les dé-sécurisées.
(5) La duplicate de la page d’accueil
Ceci est un grand classique de duplicate content. Le problème survient lorsque le nom de domaine affiche la page d’accueil qui a une url spécifique comme ceci par exemple :
Idéalement, on solutionne ces problèmes par l’architecture du site. Dans la plupart des cas il vaut mieux mettre les pages sécurisées en NOINDEX. Les pages de caddies et de finalisation de commande n’ont rien à faire dans l’index de recherche. Je vous déconseille d’utiliser des redirections 301 des pages https vers leurs versions en http, vous risquez de les dé-sécurisées.
(5) La duplicate de la page d’accueil
Ceci est un grand classique de duplicate content. Le problème survient lorsque le nom de domaine affiche la page d’accueil qui a une url spécifique comme ceci par exemple :
 Même si ce problème peut facilement être résolu en utilisant une redirection 301, la meilleure solution est d’ajouter la méta rel=canonical sur la page d’accueil sans le /index.htm pour garder une consistance et éviter les problèmes liés au duplicate content sur l’ensemble du site.
(6) IDs de Sessions
Certains sites (notamment les sites e-commerce) taguent chaque nouveau visiteur avec un paramètre de traquing. Quelquefois, ce paramètre est ajouté à l’url et est indexé, créant quelque chose comme ceci :
Même si ce problème peut facilement être résolu en utilisant une redirection 301, la meilleure solution est d’ajouter la méta rel=canonical sur la page d’accueil sans le /index.htm pour garder une consistance et éviter les problèmes liés au duplicate content sur l’ensemble du site.
(6) IDs de Sessions
Certains sites (notamment les sites e-commerce) taguent chaque nouveau visiteur avec un paramètre de traquing. Quelquefois, ce paramètre est ajouté à l’url et est indexé, créant quelque chose comme ceci :
 Ainsi, vous pouvez créer une duplicate pour chaque ID de session et combinaison de page qui sera indexé. Des ID de sessions dans les urls peuvent créer des milliers de pages de duplicate content indexés.
La meilleure option, si c’est possible dans votre cms, est de retirer l’ID de session dans les urls et de l’enregistré dans un cookie. Sinon il faudra implanter la rel=canonical sur tout le site. Eventuellement vous pouvez aussi bloquer le paramètre d’ID de session dans Outils pour les Webmasters de Google et Bing Webmaster Central.
(7) Le Tracking Affilié.
Ce problème ressemble beaucoup au cas n°6 lorsque les sites ajoutent un variable de tracking à leurs affiliés. Ces variables sont souvent dirigés vers une landing page comme ceci :
Ainsi, vous pouvez créer une duplicate pour chaque ID de session et combinaison de page qui sera indexé. Des ID de sessions dans les urls peuvent créer des milliers de pages de duplicate content indexés.
La meilleure option, si c’est possible dans votre cms, est de retirer l’ID de session dans les urls et de l’enregistré dans un cookie. Sinon il faudra implanter la rel=canonical sur tout le site. Eventuellement vous pouvez aussi bloquer le paramètre d’ID de session dans Outils pour les Webmasters de Google et Bing Webmaster Central.
(7) Le Tracking Affilié.
Ce problème ressemble beaucoup au cas n°6 lorsque les sites ajoutent un variable de tracking à leurs affiliés. Ces variables sont souvent dirigés vers une landing page comme ceci :
 C’est moins grave que le cas n°5 mais il peut créer un réel problème de duplicate content. Les solutions sont identiques au cas des urls avec des IDs de sessions. La meilleure solution est de capturer L’ID de l’affilié dans un cookie et de créer une redirection 301 vers l’url canonique de la page. Sinon vous pouvez aussi bloquer le paramètre d’url de l’affilié si possible dans votre cms.
(8) Les chemins de Duplicate Content
Créer des chemins dupliqués vers une page ne pose pas de problèmes particuliers, sauf si vos chemins dupliqués génèrent des urls dupliqués. Admettons par exemple qu’une page produit peut être atteint avec les trois façons qui suivent :
C’est moins grave que le cas n°5 mais il peut créer un réel problème de duplicate content. Les solutions sont identiques au cas des urls avec des IDs de sessions. La meilleure solution est de capturer L’ID de l’affilié dans un cookie et de créer une redirection 301 vers l’url canonique de la page. Sinon vous pouvez aussi bloquer le paramètre d’url de l’affilié si possible dans votre cms.
(8) Les chemins de Duplicate Content
Créer des chemins dupliqués vers une page ne pose pas de problèmes particuliers, sauf si vos chemins dupliqués génèrent des urls dupliqués. Admettons par exemple qu’une page produit peut être atteint avec les trois façons qui suivent :
 Dans ce cas précis, La page produit de l’Ipad2 peut être atteint par 2 catégories et un tag utilisateur généré automatiquement. Les tags utilisateurs générés automatiquement peuvent poser d’énormes problèmes internes de duplicate content car ils créent des versions illimitées de chaque page.
Idéalement, ces chemins vers une url ne devraient pas être créés du tout. Chaque page atteint ne doit avoir qu’une seule url possible en matière de SEO.
Si vous avez déjà des variantes d’une url indexée, alors une redirection 301 ou une url canonique sont à mettre en place. Assurez-vous de vérifier régulièrement dans outils pour les webmasters qu’il n’y a pas d’urls dupliqués et d’erreurs 404. Si c’est le cas vous devez revoir l’architecture de votre site.
(9) Les Paramètres Fonctionnels
Les paramètres fonctionnels sont des paramètres d’urls qui changent légèrement une page mais qui n’ont aucune valeur SEO et produisent essentiellement des pages de duplicate content. Admettons par exemple que tous vos pages produits ont une version imprimable et que la version imprimable a une url spécifique comme ceci :
Dans ce cas précis, La page produit de l’Ipad2 peut être atteint par 2 catégories et un tag utilisateur généré automatiquement. Les tags utilisateurs générés automatiquement peuvent poser d’énormes problèmes internes de duplicate content car ils créent des versions illimitées de chaque page.
Idéalement, ces chemins vers une url ne devraient pas être créés du tout. Chaque page atteint ne doit avoir qu’une seule url possible en matière de SEO.
Si vous avez déjà des variantes d’une url indexée, alors une redirection 301 ou une url canonique sont à mettre en place. Assurez-vous de vérifier régulièrement dans outils pour les webmasters qu’il n’y a pas d’urls dupliqués et d’erreurs 404. Si c’est le cas vous devez revoir l’architecture de votre site.
(9) Les Paramètres Fonctionnels
Les paramètres fonctionnels sont des paramètres d’urls qui changent légèrement une page mais qui n’ont aucune valeur SEO et produisent essentiellement des pages de duplicate content. Admettons par exemple que tous vos pages produits ont une version imprimable et que la version imprimable a une url spécifique comme ceci :
 Dans ce cas l’url “print=1” indique une version imprimable qui normalement a le même contenu mais possède un template modifié. La meilleure chose à faire et de ne pas indexer du tout les urls imprimable en utilisant une redirection 301 et mieux une url canonique.
(10) Les Duplicates Internationaux
C’est un cas classique lorsque les entreprises veulent cibler plusieurs pays à partir d’un même nom de domaine souvent en .com par simplicité. Comme dans l’exemple ci-dessous
Malheureusement, ce problème est difficile à résoudre. Google arrivera à indexé le bon contenu dans les bon pays dans la plupart des cas et dans d’autres, même avec la géolocalisation il n’y arrivera pas. C’est souvent mieux de cibler le langage plutôt que le pays à partir d’un même domaine, mais il y a souvent des cas particuliers ou il vaut mieux séparer le contenu spécifique à chaque pays, comme te tarif. La meilleure solution est d’héberger le site sur une adresse IP géo localisé dans chaque pays et dans la langue d’origine.
(11) Les Variantes de Recherche
Des résultats de recherches sur un site produisent souvent des proches duplicates en offrant des variantes d’une page en fonction de la recherche souvent en inversant le contenu de la page comme suit :
Dans ce cas l’url “print=1” indique une version imprimable qui normalement a le même contenu mais possède un template modifié. La meilleure chose à faire et de ne pas indexer du tout les urls imprimable en utilisant une redirection 301 et mieux une url canonique.
(10) Les Duplicates Internationaux
C’est un cas classique lorsque les entreprises veulent cibler plusieurs pays à partir d’un même nom de domaine souvent en .com par simplicité. Comme dans l’exemple ci-dessous
Malheureusement, ce problème est difficile à résoudre. Google arrivera à indexé le bon contenu dans les bon pays dans la plupart des cas et dans d’autres, même avec la géolocalisation il n’y arrivera pas. C’est souvent mieux de cibler le langage plutôt que le pays à partir d’un même domaine, mais il y a souvent des cas particuliers ou il vaut mieux séparer le contenu spécifique à chaque pays, comme te tarif. La meilleure solution est d’héberger le site sur une adresse IP géo localisé dans chaque pays et dans la langue d’origine.
(11) Les Variantes de Recherche
Des résultats de recherches sur un site produisent souvent des proches duplicates en offrant des variantes d’une page en fonction de la recherche souvent en inversant le contenu de la page comme suit :
 La solution et de ne pas indexer les variantes, sachant que cela peut produire plus de mal que de bien.
(13) La Pagination de Recherche
La pagination est un problème facile à comprendre mais difficile à résoudre. Chaque fois qu’on divise des recherches internes en pages séparés, vous obtenez un contenu paginé. Les urls sont facile à visualisées :
La solution et de ne pas indexer les variantes, sachant que cela peut produire plus de mal que de bien.
(13) La Pagination de Recherche
La pagination est un problème facile à comprendre mais difficile à résoudre. Chaque fois qu’on divise des recherches internes en pages séparés, vous obtenez un contenu paginé. Les urls sont facile à visualisées :
 Sur des centaines de résultats, une recherché peut facilement générer des dizaines de résultats. Alors que les résultats différent, beaucoup d’éléments importants de la page sont identiques (Title, Meta Desription, Header, Contenu, Template etc.). Ajouter à cela que Google n’est pas un grand fan du « search within search » (avoir leurs pages de résultats intégrées dans les votres).
Google à tenter, sans grand success, de résoudre le problème de la pagination. Récemment, Google a introduit Rel=Prev et Rel=Next. Initialement ça doit fonctionner mais il n’y a pas beaucoup de data pour le prouver, c’est difficile et compliqué à implémenter et des moteurs de recherche comme Bing ne le prend pas en compte.
Il y a 3 autres solutions viables qui dépendent beaucoup des situations :
Sur des centaines de résultats, une recherché peut facilement générer des dizaines de résultats. Alors que les résultats différent, beaucoup d’éléments importants de la page sont identiques (Title, Meta Desription, Header, Contenu, Template etc.). Ajouter à cela que Google n’est pas un grand fan du « search within search » (avoir leurs pages de résultats intégrées dans les votres).
Google à tenter, sans grand success, de résoudre le problème de la pagination. Récemment, Google a introduit Rel=Prev et Rel=Next. Initialement ça doit fonctionner mais il n’y a pas beaucoup de data pour le prouver, c’est difficile et compliqué à implémenter et des moteurs de recherche comme Bing ne le prend pas en compte.
Il y a 3 autres solutions viables qui dépendent beaucoup des situations :
- Vous pouvez ajouter la Meta Noindex, Follow pages 2+ des résultats de recherche. Vous laissez Google crawler le contenu paginé sans qu’ils l’index.
- Vous pouvez créer une page « view All » qui est lié à tous les résultats de recherche sur une url. Et laisser Google la détecter. Ceci est une autre option préféré de Google.
- Vous pouvez créer une page « view All » et inclure une url canonique vers cette page. Ceci n’est pas officiellement reconnu comme pratique, mais les pages ne sont plus des duplicates au sens traditionnel. Donc il se pourrait que cette méthode soit une violation de l’utilisation de la rel=canonical.
 Cela peut bien dur être tentant de vouloir indexer chaque variation, en espérant qu’ils apparaîtront tous dans les résultats de recherche, mais dans la plupart des cas cela est inutile. Mais vous pouvez soit :
Cela peut bien dur être tentant de vouloir indexer chaque variation, en espérant qu’ils apparaîtront tous dans les résultats de recherche, mais dans la plupart des cas cela est inutile. Mais vous pouvez soit :
- Faire une Rel=Next et Rel=Prev
- Inclure une url canonique à chaque variation qui redirige vers la page principal du produit.
 Depuis 2011, le SEO locale est devenu non seulement beaucoup plus compliquer, mais de plus toutes ces pages sont des “Near Duplicates”. Désormais si vous voulez vous positionner en ciblant des villes spécifiques, vous devez créer des pages par ville avec un contenu unique. Si vous avez une entreprise avec des agences ou des magasins dans plusieurs villes, alors créer une page spécifique associé à une page Google adresses sera un pari gagnant.
(16) Le Contenu Syndiqué
Un contenu syndiqué est le contenu d’un autre site publié sur le vôtre avec la permission du propriétaire de l’autre site. Donc un cas flagrant de contenu dupliqué provenant d’un autre site qui lèvera à coup sûr un drapeau rouge de la part de Google Panda voir une pénalité manuelle.
Bien que cette pratique soit légitime, il convient de créer un lien vers le contenu d’origine avec une url canonique désignant le contenu d’origine pour être certain de ne pas être pénalisé par Google Panda pour contenu dupliqué.
(17) Le Contenu Détourné
Idem que le contenu syndiqué sauf que vous ne demandez pas la permission d’autrui. GROS DRAPEAU ROUGE aux yeux de Google et de la loi.
Si vraiment un contenu d’autrui vous intéresse, alors réécrivez le en apportant vos propres points de vus ou expériences.
Formation SEO chapitre 6 : Quelle est l’Url Canonique ?
Que vous utilisiez une redirection 301 ou une url canonique, faites attention de ne pas faire l’erreur suivante :
Depuis 2011, le SEO locale est devenu non seulement beaucoup plus compliquer, mais de plus toutes ces pages sont des “Near Duplicates”. Désormais si vous voulez vous positionner en ciblant des villes spécifiques, vous devez créer des pages par ville avec un contenu unique. Si vous avez une entreprise avec des agences ou des magasins dans plusieurs villes, alors créer une page spécifique associé à une page Google adresses sera un pari gagnant.
(16) Le Contenu Syndiqué
Un contenu syndiqué est le contenu d’un autre site publié sur le vôtre avec la permission du propriétaire de l’autre site. Donc un cas flagrant de contenu dupliqué provenant d’un autre site qui lèvera à coup sûr un drapeau rouge de la part de Google Panda voir une pénalité manuelle.
Bien que cette pratique soit légitime, il convient de créer un lien vers le contenu d’origine avec une url canonique désignant le contenu d’origine pour être certain de ne pas être pénalisé par Google Panda pour contenu dupliqué.
(17) Le Contenu Détourné
Idem que le contenu syndiqué sauf que vous ne demandez pas la permission d’autrui. GROS DRAPEAU ROUGE aux yeux de Google et de la loi.
Si vraiment un contenu d’autrui vous intéresse, alors réécrivez le en apportant vos propres points de vus ou expériences.
Formation SEO chapitre 6 : Quelle est l’Url Canonique ?
Que vous utilisiez une redirection 301 ou une url canonique, faites attention de ne pas faire l’erreur suivante :
 Le problème ici est que “product.php” est une template. Vous venez de canonisé tous vos produits vers une seule url qui n’est sans doute même pas une page produit, catastrophe. Il inclut probablement aussi un paramètre comme ceci : « id=1234 »
La page canonique n’est pas toujours forcément l’url la plus simple d’une page, c’est la version la plus simple de l’url qui génère un contenu unique. Mettons que vous avez 3 urls qui génèrent la même page produit :
Le problème ici est que “product.php” est une template. Vous venez de canonisé tous vos produits vers une seule url qui n’est sans doute même pas une page produit, catastrophe. Il inclut probablement aussi un paramètre comme ceci : « id=1234 »
La page canonique n’est pas toujours forcément l’url la plus simple d’une page, c’est la version la plus simple de l’url qui génère un contenu unique. Mettons que vous avez 3 urls qui génèrent la même page produit :
 2 de ces versions sont essentiellement des pages dupliqués. La version « print » et « session ». Le paramètre id est cependant essentiel pour déterminer de quel produit il s’agit.
Conclusion :
Une mauvaise canoniqualisation peut produire des effets désastreux dans certains cas. Planifiez soigneusement et assurez-vous de sélectionner les bonnes pages à cononiqualisées avent de les consolider.
Formation SEO chapitre 7 : Les Outils pour Diagnostiquer des Contenus Dupliqués
Maintenant que vous savez à quoi ressemble un contenu dupliqué, voici quelques outils utiles pour diagnostiquer du duplicate content sur votre site internet :
(1) Google Webmaster Tools
Dans Outils pour les Webmasters de Google vous pouvez vérifier si vous avez une liste de Title et de Meta Description dupliqués que Google a crawler et identifié. Même si ça ne vous permet pas d’auditer tous les problèmes de duplicate content sur votre site, c’est un bon point de départ sachant que de nombreux urls de duplicate content auront les mêmes balises Title et Meta Description.
Dans votre compte Outils pour les Webmasters de Google, allez dans « apparence dans les résultats de recherche » puis « améliorations html » et vous verrez un tableau comme celui-ci :
2 de ces versions sont essentiellement des pages dupliqués. La version « print » et « session ». Le paramètre id est cependant essentiel pour déterminer de quel produit il s’agit.
Conclusion :
Une mauvaise canoniqualisation peut produire des effets désastreux dans certains cas. Planifiez soigneusement et assurez-vous de sélectionner les bonnes pages à cononiqualisées avent de les consolider.
Formation SEO chapitre 7 : Les Outils pour Diagnostiquer des Contenus Dupliqués
Maintenant que vous savez à quoi ressemble un contenu dupliqué, voici quelques outils utiles pour diagnostiquer du duplicate content sur votre site internet :
(1) Google Webmaster Tools
Dans Outils pour les Webmasters de Google vous pouvez vérifier si vous avez une liste de Title et de Meta Description dupliqués que Google a crawler et identifié. Même si ça ne vous permet pas d’auditer tous les problèmes de duplicate content sur votre site, c’est un bon point de départ sachant que de nombreux urls de duplicate content auront les mêmes balises Title et Meta Description.
Dans votre compte Outils pour les Webmasters de Google, allez dans « apparence dans les résultats de recherche » puis « améliorations html » et vous verrez un tableau comme celui-ci :
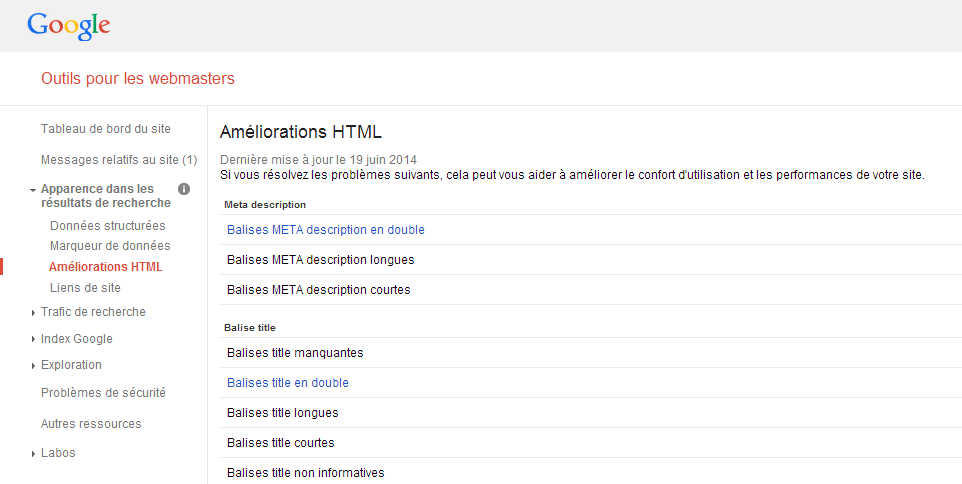 Vous pouvez cliquer sur « Balises meta description en double » et « Balises Title en double » pour voir la liste des pages dupliqués. C’est un bon moyen de démarrer.
(2) La Commande Site: de Google
Lorsque vous avez déjà une idée d’où peuvent venir les problèmes de Duplicate Content, la commande « site : » de Google est un outil puissant et flexible car vous pouvez l’utilisez en conjonction avec d’autres opérations de recherche.
Mettons par exemple que vous pensez avoir un problème de Duplicate Content sur la page d’accueil de votre site. Vous pouvez utiliser la commande « site : » avec l’opérateur « intitle » comme ceci :
Ainsi vous pouvez comprendre l’énorme avantage de suivre une formation SEO personnalisée qui vous permettra de repartir avec une stratégie SEO adapté à votre site internet ou de savoir choisir une agence SEO digne de ce nom.
Parlons en ensemble
Vous pouvez cliquer sur « Balises meta description en double » et « Balises Title en double » pour voir la liste des pages dupliqués. C’est un bon moyen de démarrer.
(2) La Commande Site: de Google
Lorsque vous avez déjà une idée d’où peuvent venir les problèmes de Duplicate Content, la commande « site : » de Google est un outil puissant et flexible car vous pouvez l’utilisez en conjonction avec d’autres opérations de recherche.
Mettons par exemple que vous pensez avoir un problème de Duplicate Content sur la page d’accueil de votre site. Vous pouvez utiliser la commande « site : » avec l’opérateur « intitle » comme ceci :
Ainsi vous pouvez comprendre l’énorme avantage de suivre une formation SEO personnalisée qui vous permettra de repartir avec une stratégie SEO adapté à votre site internet ou de savoir choisir une agence SEO digne de ce nom.
Parlons en ensemble
Laisser un commentaire